
Using the file systems on SoE cluster
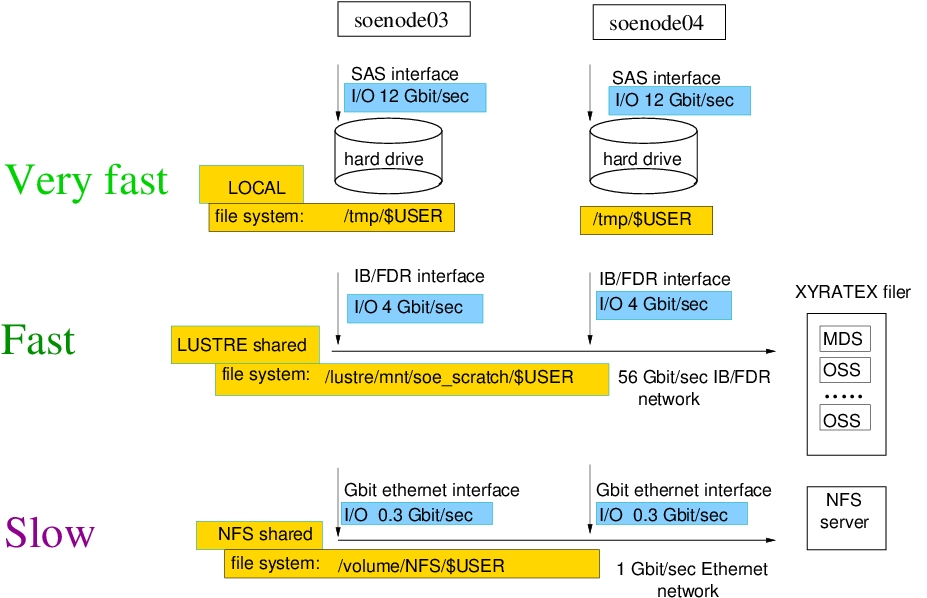
The table below shows the measured performance of the three file systems available to the cluster nodes at an average load
| File system | I/O performance |
|---|---|
Local /tmp |
12 Gbit/sec |
| LUSTRE | 4 Gbit/sec |
| NFS | 0.3 Gbit/sec |
As you can see in the digram, the /tmp is located on the local hard drives, installed on the computational nodes. If your computations run only on one node, use the /tmp for I/O during the run time to achieve the best performance. The /tmp, however, is local to the node and not accessible from the other nodes in the cluster. Therefore, you need a shared file system for multi-node message passing (MPI) computations. The cluster file system, LUSTRE, is the best suitable for MPI. The user home directories are located on the NFS file system. This is what you see when you login to soemaster1.hpc.rutgers.edu or soemaster2.hpc.rutgers.edu. Using the NFS for I/O during the computations may quickly create a bottleneck for data traffic at the NFS server. To prevent users from running their jobs on the NFS, there is a monitoring utility that terminates submitted jobs within 15 minutes unless they utilize local /tmp or LUSTRE.
How to use local /tmp
In the submit script, you need to add the commands for creating a directory under /tmp, say code>MYTMP, copying the executable and input files into MYTMP, then running the executable from there. After the computation is over, the results need to be copied back into the home directory on NFS, and TMP deleted. Below is an example of a script, openmp_batch.sh, that accomplishes such tasks:
#!/bin/bash
#SBATCH --job-name=OMP_run
#SBATCH --time=2:15:0
#SBATCH --output=slurm.out
#SBATCH --error=slurm.err
#SBATCH --partition=SOE_main
#SBATCH --ntasks-per-node=16
myrun=for.x # define executable to run
export OMP_NUM_THREADS=$SLURM_JOB_CPUS_PER_NODE # assign the number of threads for OpenMP
MYHDIR=$SLURM_SUBMIT_DIR # directory with input/output files
MYTMP="/tmp/$USER/$SLURM_JOB_ID" # local scratch directory on the node
mkdir -p $MYTMP # create scratch directory on the node
cp $MYHDIR/$myrun $MYTMP # copy the executable into the scratch
cp $MYHDIR/input1.dat $MYTMP # copy one input file into the scratch
cp $MYHDIR/input2.dat $MYTMP # copy another file into the scratch
# there may be more input files to copy
cd $MYTMP # run tasks in the scratch
./$myrun input1.dat input2.dat > run.out
cp $MYTMP/run.out $MYHDIR # copy the results data back into the home dir
rm -rf $MYTMP # remove scratch directory
Please always define MYTMP as /tmp/$USER/$SLURM_JOB_ID like shown above. When submitted to the queue system, variable $USER will be translated into your user name, and $SLURM_JOB_ID will get the job ID number. For example, when user mike submits a new job that gets job ID 1122 assigned by SLURM, the MYTMP on the computational node becomes /tmp/mike/1122. This would eliminate a chance of overwriting the MYTMP content by another job that mike may submit later.
The script can be submitted to the cluster queue with SLURM command sbatch: sbatch openmp_batch.sh More submit script examples can be found in directory /usr/local/Samples
How to use LUSTRE file system
Every user on SOE cluster is assigned a scratch space on the LUSTRE file system in /lustre/mnt/soe_scratch/$USER for parallel multi-node computations. To utilize LUSTRE for I/O during the run time, you simply need to copy your submit script, executable, and the input files into LUSTRE, then submit the run from there, for example:
cp mpi_batch.sh /lustre/mnt/soe_scratch/$USER
cp ex3.x /lustre/mnt/soe_scratch/$USER
cp input1.dat /lustre/mnt/soe_scratch/$USER
cp input2.dat /lustre/mnt/soe_scratch/$USER
cd /lustre/mnt/soe_scratch/$USER
sbatch mpi_batch.sh The computational results will be written into /lustre/mnt/soe_scratch/$USER directory. Please copy them back into your home directory and don't use LUSTRE as a long term storage:
cp stdout.out $HOME
rm /lustre/mnt/soe_scratch/$USER/*